Downloading from Scrapy Cloud¶
After you run a job on Scrapy Cloud, you can download your scraped data from Scrapy Cloud, be it from the Zyte dashboard, from a URL, or from the API.
Downloading from the Zyte dashboard¶
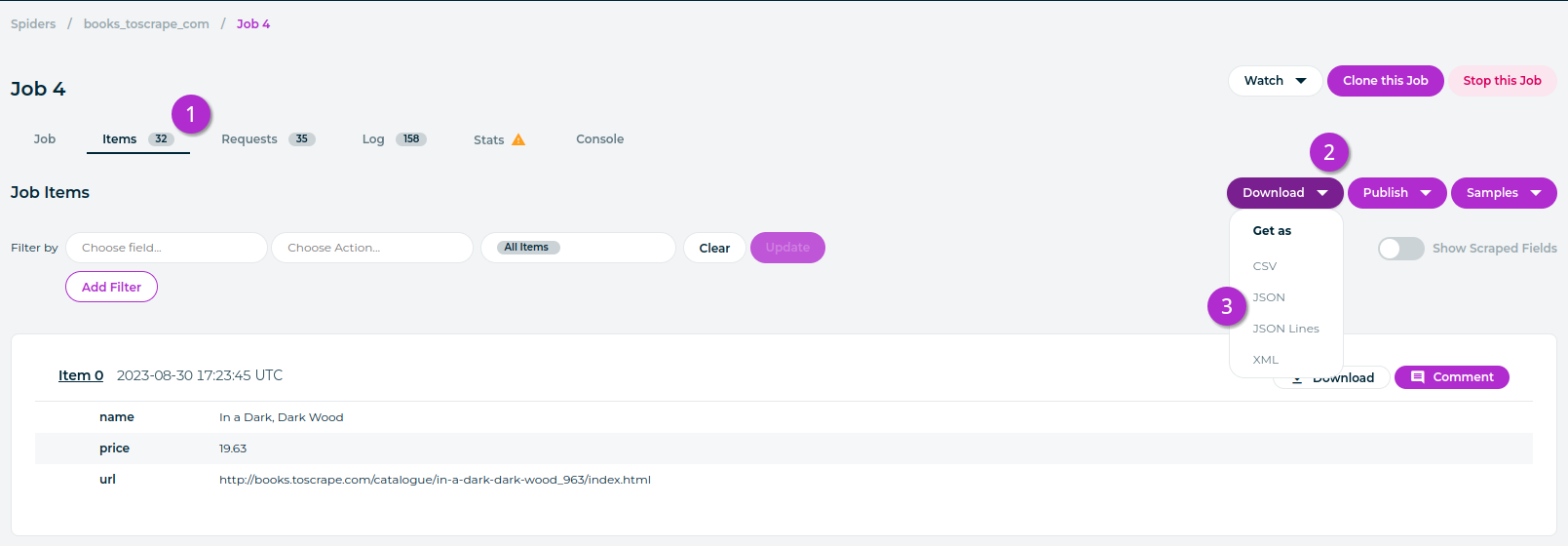
To download your job data from the Zyte dashboard:
Open the details page of your job (
https://app.zyte.com/p/<job ID>).Open the Items tab (
https://app.zyte.com/p/<job ID>/items).On the right-hand side, select Download › <format>.
<format> can be one of: CSV, JSON, JSON Lines, XML.
Download from a URL¶
Download links from the Zyte dashboard are transparent. Given a job ID and your Scrapy Cloud API key, you can build one manually, for example to automate downloads.
For JSON, JSON Lines and XML, download URLs follow this pattern:
https://storage.zyte.com/items/<job ID>?apikey=<Scrapy Cloud API key>&format=<format>
Where:
<job ID> is the job ID, e.g.
00000/0/0.<Scrapy Cloud API key> is your Scrapy Cloud API key.
<format> is the output file format, one of:
json,jl(JSON Lines),xml.
For CSV, the download URL is similar, but you:
Must specify a comma-separated list of fields to export as well, in the
fieldsquery string parameter.Can use the
include_headersquery string parameter to indicate whether you want the file names in the first row (1) or not (0, default).
For example:
https://storage.zyte.com/items/<job ID>?apikey=<Scrapy Cloud API key>&format=csv&fields=key,name,price,url&include_headers=1