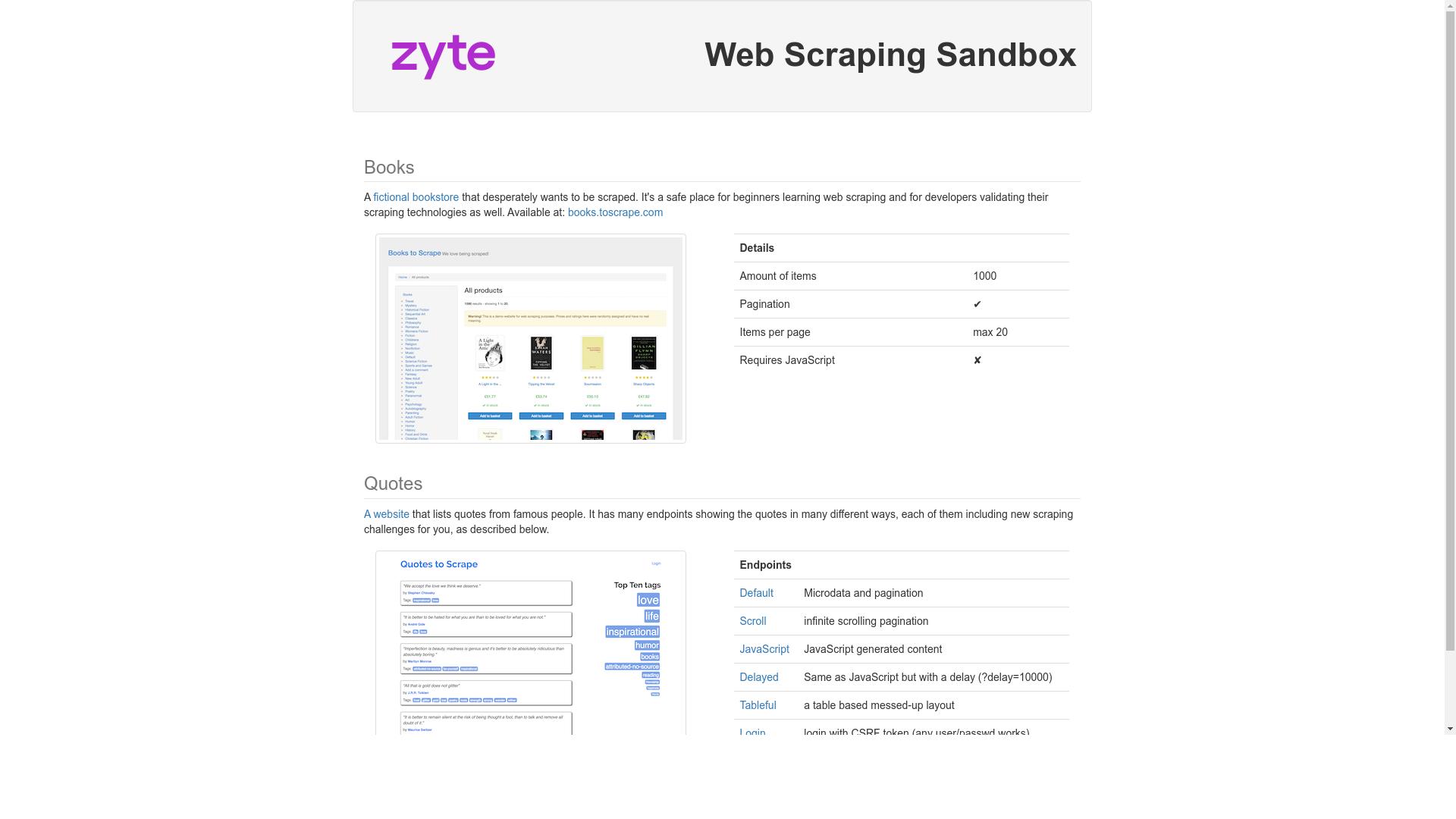
Migrating from browser automation to Zyte API¶
Learn how to migrate from browser automation tools, like Playwright, Puppeteer, Selenium, or Splash, to Zyte API.
Feature comparison¶
The following table summarizes the feature differences between Zyte API and browser automation tools:
Feature |
Zyte API |
Browser automation |
|---|---|---|
API |
HTTP |
Varies |
Website-aware API |
No |
|
Avoid bans |
Yes |
Hard |
Scalable |
Yes |
Hard |
Migration examples¶
The following examples show common browser automation functionality implemented using many browser automation tools, followed by an example of the same functionality implemented using Zyte API. Use these examples to get started porting your own code.
To learn more about the browser automation features of Zyte API, see Zyte API browser automation.
If your code requires a non-linear flow or something else that cannot be translated into a JSON array with a static sequence of actions, you may need Zyte API browser scripts.
Getting browser HTML¶
This is how you get a browser DOM rendered as HTML using browser automation tools:
Note
This example uses JavaScript with Playwright for browser automation and cheerio for HTML parsing.
const playwright = require('playwright')
async function main () {
const browser = await playwright.chromium.launch()
const page = await browser.newPage()
await page.goto('https://toscrape.com')
const browserHtml = await page.content()
await browser.close()
}
main()
Note
This example uses JavaScript with Puppeteer for browser automation and cheerio for HTML parsing.
const puppeteer = require('puppeteer')
async function main () {
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto('https://toscrape.com')
const browserHtml = await page.content()
await browser.close()
}
main()
Note
This example uses scrapy-playwright.
from scrapy import Request, Spider
class ToScrapeSpider(Spider):
name = "toscrape_com"
async def start(self):
yield Request(
"https://toscrape.com",
meta={"playwright": True},
)
def parse(self, response):
browser_html: str = response.text
Note
This example uses scrapy-splash.
from scrapy import Spider
from scrapy_splash import SplashRequest
class ToScrapeSpider(Spider):
name = "toscrape_com"
async def start(self):
yield SplashRequest("https://toscrape.com")
def parse(self, response):
browser_html: str = response.text
Note
This example uses Selenium with Python bindings for browser automation and Parsel for HTML parsing.
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://toscrape.com")
browser_html = driver.page_source
driver.close()
Note
This example uses Python with Splash for browser automation, requests to use the HTTP API of Splash, and Parsel for HTML parsing.
from urllib.parse import quote
import requests
splash_url = "YOUR_SPLASH_URL"
url = "https://toscrape.com"
response = requests.get(f"{splash_url}/render.html?url={quote(url)}")
browser_html: str = response.content.decode()
And this is how you do it using Zyte API:
Note
Install and configure code example requirements and the Zyte CA certificate to run the example below.
using System.Collections.Generic;
using System.Net;
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Threading.Tasks;
HttpClientHandler handler = new HttpClientHandler()
{
AutomaticDecompression = DecompressionMethods.All
};
HttpClient client = new HttpClient(handler);
var apiKey = "YOUR_ZYTE_API_KEY";
var bytes = Encoding.GetEncoding("ISO-8859-1").GetBytes(apiKey + ":");
var auth = System.Convert.ToBase64String(bytes);
client.DefaultRequestHeaders.Add("Authorization", "Basic " + auth);
client.DefaultRequestHeaders.Add("Accept-Encoding", "br, gzip, deflate");
var input = new Dictionary<string, object>(){
{"url", "https://toscrape.com"},
{"browserHtml", true}
};
var inputJson = JsonSerializer.Serialize(input);
var content = new StringContent(inputJson, Encoding.UTF8, "application/json");
HttpResponseMessage response = await client.PostAsync("https://api.zyte.com/v1/extract", content);
var body = await response.Content.ReadAsByteArrayAsync();
var data = JsonDocument.Parse(body);
var browserHtml = data.RootElement.GetProperty("browserHtml").ToString();
{"url": "https://toscrape.com", "browserHtml": true}
zyte-api input.jsonl \
| jq --raw-output .browserHtml
{
"url": "https://toscrape.com",
"browserHtml": true
}
curl \
--user YOUR_ZYTE_API_KEY: \
--header 'Content-Type: application/json' \
--data @input.json \
--compressed \
https://api.zyte.com/v1/extract \
| jq --raw-output .browserHtml
import com.google.common.collect.ImmutableMap;
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
import java.util.Map;
import org.apache.hc.client5.http.classic.methods.HttpPost;
import org.apache.hc.client5.http.impl.classic.CloseableHttpClient;
import org.apache.hc.client5.http.impl.classic.HttpClients;
import org.apache.hc.core5.http.ContentType;
import org.apache.hc.core5.http.HttpEntity;
import org.apache.hc.core5.http.HttpHeaders;
import org.apache.hc.core5.http.ParseException;
import org.apache.hc.core5.http.io.entity.EntityUtils;
import org.apache.hc.core5.http.io.entity.StringEntity;
class Example {
private static final String API_KEY = "YOUR_ZYTE_API_KEY";
public static void main(final String[] args)
throws InterruptedException, IOException, ParseException {
Map<String, Object> parameters =
ImmutableMap.of("url", "https://toscrape.com", "browserHtml", true);
String requestBody = new Gson().toJson(parameters);
HttpPost request = new HttpPost("https://api.zyte.com/v1/extract");
request.setHeader(HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON);
request.setHeader(HttpHeaders.ACCEPT_ENCODING, "gzip, deflate");
request.setHeader(HttpHeaders.AUTHORIZATION, buildAuthHeader());
request.setEntity(new StringEntity(requestBody));
CloseableHttpClient client = HttpClients.createDefault();
client.execute(
request,
response -> {
HttpEntity entity = response.getEntity();
String apiResponse = EntityUtils.toString(entity, StandardCharsets.UTF_8);
JsonObject jsonObject = JsonParser.parseString(apiResponse).getAsJsonObject();
String browserHtml = jsonObject.get("browserHtml").getAsString();
System.out.println(browserHtml);
return null;
});
}
private static String buildAuthHeader() {
String auth = API_KEY + ":";
String encodedAuth = Base64.getEncoder().encodeToString(auth.getBytes());
return "Basic " + encodedAuth;
}
}
const axios = require('axios')
axios.post(
'https://api.zyte.com/v1/extract',
{
url: 'https://toscrape.com',
browserHtml: true
},
{
auth: { username: 'YOUR_ZYTE_API_KEY' }
}
).then((response) => {
const browserHtml = response.data.browserHtml
})
<?php
$client = new GuzzleHttp\Client();
$response = $client->request('POST', 'https://api.zyte.com/v1/extract', [
'auth' => ['YOUR_ZYTE_API_KEY', ''],
'headers' => ['Accept-Encoding' => 'gzip'],
'json' => [
'url' => 'https://toscrape.com',
'browserHtml' => true,
],
]);
$api = json_decode($response->getBody());
$browser_html = $api->browserHtml;
curl \
--proxy api.zyte.com:8011 \
--proxy-user YOUR_ZYTE_API_KEY: \
--compressed \
-H "Zyte-Browser-Html: true" \
https://toscrape.com
import requests
api_response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={
"url": "https://toscrape.com",
"browserHtml": True,
},
)
browser_html: str = api_response.json()["browserHtml"]
import asyncio
from zyte_api import AsyncZyteAPI
async def main():
client = AsyncZyteAPI()
api_response = await client.get(
{
"url": "https://toscrape.com",
"browserHtml": True,
}
)
print(api_response["browserHtml"])
asyncio.run(main())
from scrapy import Request, Spider
class ToScrapeSpider(Spider):
name = "toscrape_com"
async def start(self):
yield Request(
"https://toscrape.com",
meta={
"zyte_api_automap": {
"browserHtml": True,
},
},
)
def parse(self, response):
browser_html: str = response.text
Output (first 5 lines):
<!DOCTYPE html><html lang="en"><head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Scraping Sandbox</title>
<link href="./css/bootstrap.min.css" rel="stylesheet">
<link href="./css/main.css" rel="stylesheet">
See Browser HTML.
Taking a screenshot¶
This is how you take a screenshot using browser automation tools:
Note
This example uses JavaScript with Playwright for browser automation and cheerio for HTML parsing.
const playwright = require('playwright')
async function main () {
const browser = await playwright.chromium.launch()
const context = await browser.newContext({ viewport: { width: 1920, height: 1080 } })
const page = await context.newPage()
await page.goto('https://toscrape.com')
const screenshot = await page.screenshot({ type: 'jpeg' })
await browser.close()
}
main()
Note
This example uses JavaScript with Puppeteer for browser automation and cheerio for HTML parsing.
const puppeteer = require('puppeteer')
async function main () {
const browser = await puppeteer.launch({ defaultViewport: { width: 1920, height: 1080 } })
const page = await browser.newPage()
await page.goto('https://toscrape.com')
const screenshot = await page.screenshot({ type: 'jpeg' })
await browser.close()
}
main()
Note
This example uses scrapy-playwright.
from scrapy import Request, Spider
from scrapy_playwright.page import PageMethod
class ToScrapeSpider(Spider):
name = "toscrape_com"
async def start(self):
yield Request(
"https://toscrape.com",
meta={
"playwright": True,
"playwright_context": "new",
"playwright_context_kwargs": {
"viewport": {"width": 1920, "height": 1080},
},
"playwright_page_methods": [
PageMethod("screenshot", type="jpeg"),
],
},
)
def parse(self, response):
screenshot: bytes = response.meta["playwright_page_methods"][0].result
Note
This example uses scrapy-splash.
from scrapy import Spider
from scrapy_splash import SplashRequest
class ToScrapeSpider(Spider):
name = "toscrape_com"
async def start(self):
yield SplashRequest(
"https://toscrape.com",
endpoint="render.jpeg",
args={
"viewport": "1920x1080",
},
)
def parse(self, response):
screenshot: bytes = response.body
Note
This example uses Selenium with Python bindings for browser automation and Parsel for HTML parsing.
from io import BytesIO
from tempfile import NamedTemporaryFile
from PIL import Image
from selenium import webdriver
# https://stackoverflow.com/a/37183295
def set_viewport_size(driver, width, height):
window_size = driver.execute_script(
"""
return [window.outerWidth - window.innerWidth + arguments[0],
window.outerHeight - window.innerHeight + arguments[1]];
""",
width,
height,
)
driver.set_window_size(*window_size)
def get_jpeg_screenshot(driver):
f = NamedTemporaryFile(suffix=".png")
driver.save_screenshot(f.name)
f.seek(0)
image = Image.open(f)
rgb_image = image.convert("RGB")
image_io = BytesIO()
rgb_image.save(image_io, format="JPEG")
return image_io.getvalue()
driver = webdriver.Firefox()
set_viewport_size(driver, 1920, 1080)
driver.get("https://toscrape.com")
screenshot = get_jpeg_screenshot(driver)
driver.close()
Note
This example uses Python with Splash for browser automation, requests to use the HTTP API of Splash, and Parsel for HTML parsing.
from urllib.parse import quote
import requests
splash_url = "YOUR_SPLASH_URL"
url = "https://toscrape.com"
response = requests.get(f"{splash_url}/render.jpeg?url={quote(url)}&viewport=1920x1080")
screenshot: bytes = response.content
And this is how you do it using Zyte API:
Note
Install and configure code example requirements and the Zyte CA certificate to run the example below.
using System.Collections.Generic;
using System.Net;
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Threading.Tasks;
HttpClientHandler handler = new HttpClientHandler()
{
AutomaticDecompression = DecompressionMethods.All
};
HttpClient client = new HttpClient(handler);
var apiKey = "YOUR_ZYTE_API_KEY";
var bytes = Encoding.GetEncoding("ISO-8859-1").GetBytes(apiKey + ":");
var auth = System.Convert.ToBase64String(bytes);
client.DefaultRequestHeaders.Add("Authorization", "Basic " + auth);
client.DefaultRequestHeaders.Add("Accept-Encoding", "br, gzip, deflate");
var input = new Dictionary<string, object>(){
{"url", "https://toscrape.com"},
{"screenshot", true}
};
var inputJson = JsonSerializer.Serialize(input);
var content = new StringContent(inputJson, Encoding.UTF8, "application/json");
HttpResponseMessage response = await client.PostAsync("https://api.zyte.com/v1/extract", content);
var body = await response.Content.ReadAsByteArrayAsync();
var data = JsonDocument.Parse(body);
var base64Screenshot = data.RootElement.GetProperty("screenshot").ToString();
var screenshot = System.Convert.FromBase64String(base64Screenshot);
{"url": "https://toscrape.com", "screenshot": true}
zyte-api input.jsonl \
| jq --raw-output .screenshot \
| base64 --decode \
> screenshot.jpg
{
"url": "https://toscrape.com",
"screenshot": true
}
curl \
--user YOUR_ZYTE_API_KEY: \
--header 'Content-Type: application/json' \
--data @input.json \
--compressed \
https://api.zyte.com/v1/extract \
| jq --raw-output .screenshot \
| base64 --decode \
> screenshot.jpg
import com.google.common.collect.ImmutableMap;
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
import java.util.Map;
import org.apache.hc.client5.http.classic.methods.HttpPost;
import org.apache.hc.client5.http.impl.classic.CloseableHttpClient;
import org.apache.hc.client5.http.impl.classic.HttpClients;
import org.apache.hc.core5.http.ContentType;
import org.apache.hc.core5.http.HttpEntity;
import org.apache.hc.core5.http.HttpHeaders;
import org.apache.hc.core5.http.ParseException;
import org.apache.hc.core5.http.io.entity.EntityUtils;
import org.apache.hc.core5.http.io.entity.StringEntity;
class Example {
private static final String API_KEY = "YOUR_ZYTE_API_KEY";
public static void main(final String[] args)
throws InterruptedException, IOException, ParseException {
Map<String, Object> parameters =
ImmutableMap.of("url", "https://toscrape.com", "screenshot", true);
String requestBody = new Gson().toJson(parameters);
HttpPost request = new HttpPost("https://api.zyte.com/v1/extract");
request.setHeader(HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON);
request.setHeader(HttpHeaders.ACCEPT_ENCODING, "gzip, deflate");
request.setHeader(HttpHeaders.AUTHORIZATION, buildAuthHeader());
request.setEntity(new StringEntity(requestBody));
CloseableHttpClient client = HttpClients.createDefault();
client.execute(
request,
response -> {
HttpEntity entity = response.getEntity();
String apiResponse = EntityUtils.toString(entity, StandardCharsets.UTF_8);
JsonObject jsonObject = JsonParser.parseString(apiResponse).getAsJsonObject();
String base64Screenshot = jsonObject.get("screenshot").getAsString();
byte[] screenshot = Base64.getDecoder().decode(base64Screenshot);
try (FileOutputStream fos = new FileOutputStream("screenshot.jpg")) {
fos.write(screenshot);
}
return null;
});
}
private static String buildAuthHeader() {
String auth = API_KEY + ":";
String encodedAuth = Base64.getEncoder().encodeToString(auth.getBytes());
return "Basic " + encodedAuth;
}
}
const axios = require('axios')
axios.post(
'https://api.zyte.com/v1/extract',
{
url: 'https://toscrape.com',
screenshot: true
},
{
auth: { username: 'YOUR_ZYTE_API_KEY' }
}
).then((response) => {
const screenshot = Buffer.from(response.data.screenshot, 'base64')
})
<?php
$client = new GuzzleHttp\Client();
$response = $client->request('POST', 'https://api.zyte.com/v1/extract', [
'auth' => ['YOUR_ZYTE_API_KEY', ''],
'headers' => ['Accept-Encoding' => 'gzip'],
'json' => [
'url' => 'https://toscrape.com',
'screenshot' => true,
],
]);
$api = json_decode($response->getBody());
$screenshot = base64_decode($api->screenshot);
from base64 import b64decode
import requests
api_response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={
"url": "https://toscrape.com",
"screenshot": True,
},
)
screenshot: bytes = b64decode(api_response.json()["screenshot"])
import asyncio
from base64 import b64decode
from zyte_api import AsyncZyteAPI
async def main():
client = AsyncZyteAPI()
api_response = await client.get(
{
"url": "https://toscrape.com",
"screenshot": True,
}
)
screenshot = b64decode(api_response["screenshot"])
with open("screenshot.jpg", "wb") as f:
f.write(screenshot)
asyncio.run(main())
from base64 import b64decode
from scrapy import Request, Spider
class ToScrapeComSpider(Spider):
name = "toscrape_com"
async def start(self):
yield Request(
"https://toscrape.com",
meta={
"zyte_api_automap": {
"screenshot": True,
},
},
)
def parse(self, response):
screenshot: bytes = b64decode(response.raw_api_response["screenshot"])
Output:
See Screenshot.
Consuming scroll-based pagination¶
This is how you use browser automation tools to load a webpage on a web browser, scroll to the bottom in a loop until it stops loading more content, and get the resulting DOM rendered as HTML:
Note
This example uses JavaScript with Playwright for browser automation and cheerio for HTML parsing.
const cheerio = require('cheerio')
const playwright = require('playwright')
async function main () {
const browser = await playwright.chromium.launch()
const page = await browser.newPage()
await page.goto('https://quotes.toscrape.com/scroll')
await page.evaluate(async () => {
const scrollInterval = setInterval(
function () {
const scrollingElement = (document.scrollingElement || document.body)
scrollingElement.scrollTop = scrollingElement.scrollHeight
},
100
)
let previousHeight = null
while (true) {
const currentHeight = window.innerHeight + window.scrollY
if (!previousHeight) {
previousHeight = currentHeight
await new Promise(resolve => setTimeout(resolve, 500))
} else if (previousHeight === currentHeight) {
clearInterval(scrollInterval)
break
} else {
previousHeight = currentHeight
await new Promise(resolve => setTimeout(resolve, 500))
}
}
})
const $ = cheerio.load(await page.content())
const quoteCount = $('.quote').length
await browser.close()
}
main()
Note
This example uses JavaScript with Puppeteer for browser automation and cheerio for HTML parsing.
const cheerio = require('cheerio')
const puppeteer = require('puppeteer')
async function main () {
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto('https://quotes.toscrape.com/scroll')
await page.evaluate(async () => {
const scrollInterval = setInterval(
function () {
const scrollingElement = (document.scrollingElement || document.body)
scrollingElement.scrollTop = scrollingElement.scrollHeight
},
100
)
let previousHeight = null
while (true) {
const currentHeight = window.innerHeight + window.scrollY
if (!previousHeight) {
previousHeight = currentHeight
await new Promise(resolve => setTimeout(resolve, 500))
} else if (previousHeight === currentHeight) {
clearInterval(scrollInterval)
break
} else {
previousHeight = currentHeight
await new Promise(resolve => setTimeout(resolve, 500))
}
}
})
const $ = cheerio.load(await page.content())
const quoteCount = $('.quote').length
await browser.close()
}
main()
Note
This example uses scrapy-playwright.
from asyncio import sleep
from scrapy import Request, Spider
class QuotesToScrapeComSpider(Spider):
name = "quotes_toscrape_com"
async def start(self):
yield Request(
"https://quotes.toscrape.com/scroll",
meta={
"playwright": True,
"playwright_include_page": True,
},
)
# Based on https://stackoverflow.com/a/69193325
async def scroll_to_bottom(self, page):
await page.evaluate(
"""
var scrollInterval = setInterval(
function () {
var scrollingElement = (document.scrollingElement || document.body);
scrollingElement.scrollTop = scrollingElement.scrollHeight;
},
100
);
"""
)
previous_height = None
while True:
current_height = await page.evaluate(
"(window.innerHeight + window.scrollY)"
)
if not previous_height:
previous_height = current_height
await sleep(0.5)
elif previous_height == current_height:
await page.evaluate("clearInterval(scrollInterval)")
break
else:
previous_height = current_height
await sleep(0.5)
async def parse(self, response):
page = response.meta["playwright_page"]
await self.scroll_to_bottom(page)
body = await page.content()
response = response.replace(body=body)
quote_count = len(response.css(".quote"))
await page.close()
Note
This example uses scrapy-splash.
from scrapy import Spider
from scrapy_splash import SplashRequest
# Based on https://stackoverflow.com/a/40366442
SCROLL_TO_BOTTOM_LUA = """
function main(splash)
local num_scrolls = 10
local scroll_delay = 0.1
local scroll_to = splash:jsfunc("window.scrollTo")
local get_body_height = splash:jsfunc(
"function() {return document.body.scrollHeight;}"
)
assert(splash:go(splash.args.url))
for _ = 1, num_scrolls do
scroll_to(0, get_body_height())
splash:wait(scroll_delay)
end
return splash:html()
end
"""
class QuotesToScrapeComSpider(Spider):
name = "quotes_toscrape_com"
async def start(self):
yield SplashRequest(
"https://quotes.toscrape.com/scroll",
endpoint="execute",
args={"lua_source": SCROLL_TO_BOTTOM_LUA},
)
def parse(self, response):
quote_count = len(response.css(".quote"))
Note
This example uses Selenium with Python bindings for browser automation and Parsel for HTML parsing.
from time import sleep
from parsel import Selector
from selenium import webdriver
# Based on https://stackoverflow.com/a/69193325
def scroll_to_bottom(driver):
driver.execute_script(
"""
var scrollInterval = setInterval(
function () {
var scrollingElement = (document.scrollingElement || document.body);
scrollingElement.scrollTop = scrollingElement.scrollHeight;
},
100
);
"""
)
previous_height = None
while True:
current_height = driver.execute_script(
"return window.innerHeight + window.scrollY"
)
if not previous_height:
previous_height = current_height
sleep(0.5)
elif previous_height == current_height:
driver.execute_script("clearInterval(window.scrollInterval)")
break
else:
previous_height = current_height
sleep(0.5)
driver = webdriver.Firefox()
driver.get("https://quotes.toscrape.com/scroll")
scroll_to_bottom(driver)
selector = Selector(driver.page_source)
quote_count = len(selector.css(".quote"))
driver.close()
Note
This example uses Python with Splash for browser automation, requests to use the HTTP API of Splash, and Parsel for HTML parsing.
from urllib.parse import quote
import requests
from parsel import Selector
# Based on https://stackoverflow.com/a/40366442
SCROLL_TO_BOTTOM_LUA = """
function main(splash)
local num_scrolls = 10
local scroll_delay = 0.1
local scroll_to = splash:jsfunc("window.scrollTo")
local get_body_height = splash:jsfunc(
"function() {return document.body.scrollHeight;}"
)
assert(splash:go(splash.args.url))
for _ = 1, num_scrolls do
scroll_to(0, get_body_height())
splash:wait(scroll_delay)
end
return splash:html()
end
"""
splash_url = "YOUR_SPLASH_URL"
url = "https://quotes.toscrape.com/scroll"
response = requests.get(
f"{splash_url}/execute?url={quote(url)}&lua_source={quote(SCROLL_TO_BOTTOM_LUA)}"
)
selector = Selector(text=response.content.decode())
quote_count = len(selector.css(".quote"))
And this is how you do it using Zyte API:
Note
Install and configure code example requirements and the Zyte CA certificate to run the example below.
using System.Collections.Generic;
using System.Net;
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Threading.Tasks;
using HtmlAgilityPack;
HttpClientHandler handler = new HttpClientHandler()
{
AutomaticDecompression = DecompressionMethods.All
};
HttpClient client = new HttpClient(handler);
var apiKey = "YOUR_ZYTE_API_KEY";
var bytes = Encoding.GetEncoding("ISO-8859-1").GetBytes(apiKey + ":");
var auth = System.Convert.ToBase64String(bytes);
client.DefaultRequestHeaders.Add("Authorization", "Basic " + auth);
client.DefaultRequestHeaders.Add("Accept-Encoding", "br, gzip, deflate");
var input = new Dictionary<string, object>(){
{"url", "https://quotes.toscrape.com/scroll"},
{"browserHtml", true},
{
"actions",
new List<Dictionary<string, object>>()
{
new Dictionary<string, object>()
{
{"action", "scrollBottom"}
}
}
}
};
var inputJson = JsonSerializer.Serialize(input);
var content = new StringContent(inputJson, Encoding.UTF8, "application/json");
HttpResponseMessage response = await client.PostAsync("https://api.zyte.com/v1/extract", content);
var body = await response.Content.ReadAsByteArrayAsync();
var data = JsonDocument.Parse(body);
var browserHtml = data.RootElement.GetProperty("browserHtml").ToString();
var htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(browserHtml);
var navigator = htmlDocument.CreateNavigator();
var quoteCount = (double)navigator.Evaluate("count(//*[@class=\"quote\"])");
{"url": "https://quotes.toscrape.com/scroll", "browserHtml": true, "actions": [{"action": "scrollBottom"}]}
zyte-api input.jsonl \
| jq --raw-output .browserHtml \
| xmllint --html --xpath 'count(//*[@class="quote"])' - 2> /dev/null
{
"url": "https://quotes.toscrape.com/scroll",
"browserHtml": true,
"actions": [
{
"action": "scrollBottom"
}
]
}
curl \
--user YOUR_ZYTE_API_KEY: \
--header 'Content-Type: application/json' \
--data @input.json \
--compressed \
https://api.zyte.com/v1/extract \
| jq --raw-output .browserHtml \
| xmllint --html --xpath 'count(//*[@class="quote"])' - 2> /dev/null
import com.google.common.collect.ImmutableMap;
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
import java.util.Collections;
import java.util.Map;
import org.apache.hc.client5.http.classic.methods.HttpPost;
import org.apache.hc.client5.http.impl.classic.CloseableHttpClient;
import org.apache.hc.client5.http.impl.classic.HttpClients;
import org.apache.hc.core5.http.ContentType;
import org.apache.hc.core5.http.HttpEntity;
import org.apache.hc.core5.http.HttpHeaders;
import org.apache.hc.core5.http.ParseException;
import org.apache.hc.core5.http.io.entity.EntityUtils;
import org.apache.hc.core5.http.io.entity.StringEntity;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
class Example {
private static final String API_KEY = "YOUR_ZYTE_API_KEY";
public static void main(final String[] args)
throws InterruptedException, IOException, ParseException {
Map<String, Object> action = ImmutableMap.of("action", "scrollBottom");
Map<String, Object> parameters =
ImmutableMap.of(
"url",
"https://quotes.toscrape.com/scroll",
"browserHtml",
true,
"actions",
Collections.singletonList(action));
String requestBody = new Gson().toJson(parameters);
HttpPost request = new HttpPost("https://api.zyte.com/v1/extract");
request.setHeader(HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON);
request.setHeader(HttpHeaders.ACCEPT_ENCODING, "gzip, deflate");
request.setHeader(HttpHeaders.AUTHORIZATION, buildAuthHeader());
request.setEntity(new StringEntity(requestBody));
CloseableHttpClient client = HttpClients.createDefault();
client.execute(
request,
response -> {
HttpEntity entity = response.getEntity();
String apiResponse = EntityUtils.toString(entity, StandardCharsets.UTF_8);
JsonObject jsonObject = JsonParser.parseString(apiResponse).getAsJsonObject();
String browserHtml = jsonObject.get("browserHtml").getAsString();
Document document = Jsoup.parse(browserHtml);
int quoteCount = document.select(".quote").size();
System.out.println(quoteCount);
return null;
});
}
private static String buildAuthHeader() {
String auth = API_KEY + ":";
String encodedAuth = Base64.getEncoder().encodeToString(auth.getBytes());
return "Basic " + encodedAuth;
}
}
const axios = require('axios')
const cheerio = require('cheerio')
axios.post(
'https://api.zyte.com/v1/extract',
{
url: 'https://quotes.toscrape.com/scroll',
browserHtml: true,
actions: [
{
action: 'scrollBottom'
}
]
},
{
auth: { username: 'YOUR_ZYTE_API_KEY' }
}
).then((response) => {
const browserHtml = response.data.browserHtml
const $ = cheerio.load(browserHtml)
const quoteCount = $('.quote').length
})
<?php
$client = new GuzzleHttp\Client();
$response = $client->request('POST', 'https://api.zyte.com/v1/extract', [
'auth' => ['YOUR_ZYTE_API_KEY', ''],
'headers' => ['Accept-Encoding' => 'gzip'],
'json' => [
'url' => 'https://quotes.toscrape.com/scroll',
'browserHtml' => true,
'actions' => [
['action' => 'scrollBottom'],
],
],
]);
$data = json_decode($response->getBody());
$doc = new DOMDocument();
$doc->loadHTML($data->browserHtml);
$xpath = new DOMXPath($doc);
$quote_count = $xpath->query("//*[@class='quote']")->count();
import requests
from parsel import Selector
api_response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={
"url": "https://quotes.toscrape.com/scroll",
"browserHtml": True,
"actions": [
{
"action": "scrollBottom",
},
],
},
)
browser_html = api_response.json()["browserHtml"]
quote_count = len(Selector(browser_html).css(".quote"))
import asyncio
from parsel import Selector
from zyte_api import AsyncZyteAPI
async def main():
client = AsyncZyteAPI()
api_response = await client.get(
{
"url": "https://quotes.toscrape.com/scroll",
"browserHtml": True,
"actions": [
{
"action": "scrollBottom",
},
],
},
)
browser_html = api_response["browserHtml"]
quote_count = len(Selector(browser_html).css(".quote"))
print(quote_count)
asyncio.run(main())
from scrapy import Request, Spider
class QuotesToScrapeComSpider(Spider):
name = "quotes_toscrape_com"
async def start(self):
yield Request(
"https://quotes.toscrape.com/scroll",
meta={
"zyte_api_automap": {
"browserHtml": True,
"actions": [
{
"action": "scrollBottom",
},
],
},
},
)
def parse(self, response):
quote_count = len(response.css(".quote"))
Output:
100
See Actions.