Zyte API browser automation¶
You can use browser automation through Zyte API to get browser-rendered HTML, screenshots, or both.
For browser requests, Zyte API also supports:
Actions, network capture, request headers, redirection, and toggling JavaScript.
Geolocation, IP type, cookies, sessions, redirection, response headers, and metadata.
Unlike HTTP requests, browser requests do not support:
An HTTP request method, body, or header other than Referer.
Returning non-HTML response data, other than a screenshot.
All browser request features are also available for automatic extraction requests that use a browser request as extraction source.
Browser HTML¶
Browser HTML is the HTML representation of the Document Object Model (DOM) of a webpage after it has been rendered in a browser.
To get browser HTML, set the browserHtml request field to
true. The browserHtml response field is the browser HTML
as a string.
Note
By default, iframes in browserHtml are empty. Set
includeIframes to true to embed iframe content in
browserHtml.
To access content from the shadow DOM, check out the corresponding example under Actions.
See also HTML and browser HTML.
Example
Note
Install and configure code example requirements and the Zyte CA certificate to run the example below.
using System.Collections.Generic;
using System.Net;
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Threading.Tasks;
HttpClientHandler handler = new HttpClientHandler()
{
AutomaticDecompression = DecompressionMethods.All
};
HttpClient client = new HttpClient(handler);
var apiKey = "YOUR_ZYTE_API_KEY";
var bytes = Encoding.GetEncoding("ISO-8859-1").GetBytes(apiKey + ":");
var auth = System.Convert.ToBase64String(bytes);
client.DefaultRequestHeaders.Add("Authorization", "Basic " + auth);
client.DefaultRequestHeaders.Add("Accept-Encoding", "br, gzip, deflate");
var input = new Dictionary<string, object>(){
{"url", "https://toscrape.com"},
{"browserHtml", true}
};
var inputJson = JsonSerializer.Serialize(input);
var content = new StringContent(inputJson, Encoding.UTF8, "application/json");
HttpResponseMessage response = await client.PostAsync("https://api.zyte.com/v1/extract", content);
var body = await response.Content.ReadAsByteArrayAsync();
var data = JsonDocument.Parse(body);
var browserHtml = data.RootElement.GetProperty("browserHtml").ToString();
{"url": "https://toscrape.com", "browserHtml": true}
zyte-api input.jsonl \
| jq --raw-output .browserHtml
{
"url": "https://toscrape.com",
"browserHtml": true
}
curl \
--user YOUR_ZYTE_API_KEY: \
--header 'Content-Type: application/json' \
--data @input.json \
--compressed \
https://api.zyte.com/v1/extract \
| jq --raw-output .browserHtml
import com.google.common.collect.ImmutableMap;
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
import java.util.Map;
import org.apache.hc.client5.http.classic.methods.HttpPost;
import org.apache.hc.client5.http.impl.classic.CloseableHttpClient;
import org.apache.hc.client5.http.impl.classic.HttpClients;
import org.apache.hc.core5.http.ContentType;
import org.apache.hc.core5.http.HttpEntity;
import org.apache.hc.core5.http.HttpHeaders;
import org.apache.hc.core5.http.ParseException;
import org.apache.hc.core5.http.io.entity.EntityUtils;
import org.apache.hc.core5.http.io.entity.StringEntity;
class Example {
private static final String API_KEY = "YOUR_ZYTE_API_KEY";
public static void main(final String[] args)
throws InterruptedException, IOException, ParseException {
Map<String, Object> parameters =
ImmutableMap.of("url", "https://toscrape.com", "browserHtml", true);
String requestBody = new Gson().toJson(parameters);
HttpPost request = new HttpPost("https://api.zyte.com/v1/extract");
request.setHeader(HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON);
request.setHeader(HttpHeaders.ACCEPT_ENCODING, "gzip, deflate");
request.setHeader(HttpHeaders.AUTHORIZATION, buildAuthHeader());
request.setEntity(new StringEntity(requestBody));
CloseableHttpClient client = HttpClients.createDefault();
client.execute(
request,
response -> {
HttpEntity entity = response.getEntity();
String apiResponse = EntityUtils.toString(entity, StandardCharsets.UTF_8);
JsonObject jsonObject = JsonParser.parseString(apiResponse).getAsJsonObject();
String browserHtml = jsonObject.get("browserHtml").getAsString();
System.out.println(browserHtml);
return null;
});
}
private static String buildAuthHeader() {
String auth = API_KEY + ":";
String encodedAuth = Base64.getEncoder().encodeToString(auth.getBytes());
return "Basic " + encodedAuth;
}
}
const axios = require('axios')
axios.post(
'https://api.zyte.com/v1/extract',
{
url: 'https://toscrape.com',
browserHtml: true
},
{
auth: { username: 'YOUR_ZYTE_API_KEY' }
}
).then((response) => {
const browserHtml = response.data.browserHtml
})
<?php
$client = new GuzzleHttp\Client();
$response = $client->request('POST', 'https://api.zyte.com/v1/extract', [
'auth' => ['YOUR_ZYTE_API_KEY', ''],
'headers' => ['Accept-Encoding' => 'gzip'],
'json' => [
'url' => 'https://toscrape.com',
'browserHtml' => true,
],
]);
$api = json_decode($response->getBody());
$browser_html = $api->browserHtml;
curl \
--proxy api.zyte.com:8011 \
--proxy-user YOUR_ZYTE_API_KEY: \
--compressed \
-H "Zyte-Browser-Html: true" \
https://toscrape.com
import requests
api_response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={
"url": "https://toscrape.com",
"browserHtml": True,
},
)
browser_html: str = api_response.json()["browserHtml"]
import asyncio
from zyte_api import AsyncZyteAPI
async def main():
client = AsyncZyteAPI()
api_response = await client.get(
{
"url": "https://toscrape.com",
"browserHtml": True,
}
)
print(api_response["browserHtml"])
asyncio.run(main())
from scrapy import Request, Spider
class ToScrapeSpider(Spider):
name = "toscrape_com"
async def start(self):
yield Request(
"https://toscrape.com",
meta={
"zyte_api_automap": {
"browserHtml": True,
},
},
)
def parse(self, response):
browser_html: str = response.text
Output (first 5 lines):
<!DOCTYPE html><html lang="en"><head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Scraping Sandbox</title>
<link href="./css/bootstrap.min.css" rel="stylesheet">
<link href="./css/main.css" rel="stylesheet">
Screenshot¶
To get a webpage screenshot in browser requests, set the
screenshot request field to true . The
screenshot response field is the Base64-encoded screenshot
file data.
Example
Note
Install and configure code example requirements and the Zyte CA certificate to run the example below.
using System.Collections.Generic;
using System.Net;
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Threading.Tasks;
HttpClientHandler handler = new HttpClientHandler()
{
AutomaticDecompression = DecompressionMethods.All
};
HttpClient client = new HttpClient(handler);
var apiKey = "YOUR_ZYTE_API_KEY";
var bytes = Encoding.GetEncoding("ISO-8859-1").GetBytes(apiKey + ":");
var auth = System.Convert.ToBase64String(bytes);
client.DefaultRequestHeaders.Add("Authorization", "Basic " + auth);
client.DefaultRequestHeaders.Add("Accept-Encoding", "br, gzip, deflate");
var input = new Dictionary<string, object>(){
{"url", "https://toscrape.com"},
{"screenshot", true}
};
var inputJson = JsonSerializer.Serialize(input);
var content = new StringContent(inputJson, Encoding.UTF8, "application/json");
HttpResponseMessage response = await client.PostAsync("https://api.zyte.com/v1/extract", content);
var body = await response.Content.ReadAsByteArrayAsync();
var data = JsonDocument.Parse(body);
var base64Screenshot = data.RootElement.GetProperty("screenshot").ToString();
var screenshot = System.Convert.FromBase64String(base64Screenshot);
{"url": "https://toscrape.com", "screenshot": true}
zyte-api input.jsonl \
| jq --raw-output .screenshot \
| base64 --decode \
> screenshot.jpg
{
"url": "https://toscrape.com",
"screenshot": true
}
curl \
--user YOUR_ZYTE_API_KEY: \
--header 'Content-Type: application/json' \
--data @input.json \
--compressed \
https://api.zyte.com/v1/extract \
| jq --raw-output .screenshot \
| base64 --decode \
> screenshot.jpg
import com.google.common.collect.ImmutableMap;
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
import java.util.Map;
import org.apache.hc.client5.http.classic.methods.HttpPost;
import org.apache.hc.client5.http.impl.classic.CloseableHttpClient;
import org.apache.hc.client5.http.impl.classic.HttpClients;
import org.apache.hc.core5.http.ContentType;
import org.apache.hc.core5.http.HttpEntity;
import org.apache.hc.core5.http.HttpHeaders;
import org.apache.hc.core5.http.ParseException;
import org.apache.hc.core5.http.io.entity.EntityUtils;
import org.apache.hc.core5.http.io.entity.StringEntity;
class Example {
private static final String API_KEY = "YOUR_ZYTE_API_KEY";
public static void main(final String[] args)
throws InterruptedException, IOException, ParseException {
Map<String, Object> parameters =
ImmutableMap.of("url", "https://toscrape.com", "screenshot", true);
String requestBody = new Gson().toJson(parameters);
HttpPost request = new HttpPost("https://api.zyte.com/v1/extract");
request.setHeader(HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON);
request.setHeader(HttpHeaders.ACCEPT_ENCODING, "gzip, deflate");
request.setHeader(HttpHeaders.AUTHORIZATION, buildAuthHeader());
request.setEntity(new StringEntity(requestBody));
CloseableHttpClient client = HttpClients.createDefault();
client.execute(
request,
response -> {
HttpEntity entity = response.getEntity();
String apiResponse = EntityUtils.toString(entity, StandardCharsets.UTF_8);
JsonObject jsonObject = JsonParser.parseString(apiResponse).getAsJsonObject();
String base64Screenshot = jsonObject.get("screenshot").getAsString();
byte[] screenshot = Base64.getDecoder().decode(base64Screenshot);
try (FileOutputStream fos = new FileOutputStream("screenshot.jpg")) {
fos.write(screenshot);
}
return null;
});
}
private static String buildAuthHeader() {
String auth = API_KEY + ":";
String encodedAuth = Base64.getEncoder().encodeToString(auth.getBytes());
return "Basic " + encodedAuth;
}
}
const axios = require('axios')
axios.post(
'https://api.zyte.com/v1/extract',
{
url: 'https://toscrape.com',
screenshot: true
},
{
auth: { username: 'YOUR_ZYTE_API_KEY' }
}
).then((response) => {
const screenshot = Buffer.from(response.data.screenshot, 'base64')
})
<?php
$client = new GuzzleHttp\Client();
$response = $client->request('POST', 'https://api.zyte.com/v1/extract', [
'auth' => ['YOUR_ZYTE_API_KEY', ''],
'headers' => ['Accept-Encoding' => 'gzip'],
'json' => [
'url' => 'https://toscrape.com',
'screenshot' => true,
],
]);
$api = json_decode($response->getBody());
$screenshot = base64_decode($api->screenshot);
from base64 import b64decode
import requests
api_response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={
"url": "https://toscrape.com",
"screenshot": True,
},
)
screenshot: bytes = b64decode(api_response.json()["screenshot"])
import asyncio
from base64 import b64decode
from zyte_api import AsyncZyteAPI
async def main():
client = AsyncZyteAPI()
api_response = await client.get(
{
"url": "https://toscrape.com",
"screenshot": True,
}
)
screenshot = b64decode(api_response["screenshot"])
with open("screenshot.jpg", "wb") as f:
f.write(screenshot)
asyncio.run(main())
from base64 import b64decode
from scrapy import Request, Spider
class ToScrapeComSpider(Spider):
name = "toscrape_com"
async def start(self):
yield Request(
"https://toscrape.com",
meta={
"zyte_api_automap": {
"screenshot": True,
},
},
)
def parse(self, response):
screenshot: bytes = b64decode(response.raw_api_response["screenshot"])
Output:
Actions¶
In browser requests use the actions request field to define a sequence of browser actions to perform before output generation.
See also
Example: scrollBottom
Note
Install and configure code example requirements and the Zyte CA certificate to run the example below.
using System.Collections.Generic;
using System.Net;
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Threading.Tasks;
using HtmlAgilityPack;
HttpClientHandler handler = new HttpClientHandler()
{
AutomaticDecompression = DecompressionMethods.All
};
HttpClient client = new HttpClient(handler);
var apiKey = "YOUR_ZYTE_API_KEY";
var bytes = Encoding.GetEncoding("ISO-8859-1").GetBytes(apiKey + ":");
var auth = System.Convert.ToBase64String(bytes);
client.DefaultRequestHeaders.Add("Authorization", "Basic " + auth);
client.DefaultRequestHeaders.Add("Accept-Encoding", "br, gzip, deflate");
var input = new Dictionary<string, object>(){
{"url", "https://quotes.toscrape.com/scroll"},
{"browserHtml", true},
{
"actions",
new List<Dictionary<string, object>>()
{
new Dictionary<string, object>()
{
{"action", "scrollBottom"}
}
}
}
};
var inputJson = JsonSerializer.Serialize(input);
var content = new StringContent(inputJson, Encoding.UTF8, "application/json");
HttpResponseMessage response = await client.PostAsync("https://api.zyte.com/v1/extract", content);
var body = await response.Content.ReadAsByteArrayAsync();
var data = JsonDocument.Parse(body);
var browserHtml = data.RootElement.GetProperty("browserHtml").ToString();
var htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(browserHtml);
var navigator = htmlDocument.CreateNavigator();
var quoteCount = (double)navigator.Evaluate("count(//*[@class=\"quote\"])");
{"url": "https://quotes.toscrape.com/scroll", "browserHtml": true, "actions": [{"action": "scrollBottom"}]}
zyte-api input.jsonl \
| jq --raw-output .browserHtml \
| xmllint --html --xpath 'count(//*[@class="quote"])' - 2> /dev/null
{
"url": "https://quotes.toscrape.com/scroll",
"browserHtml": true,
"actions": [
{
"action": "scrollBottom"
}
]
}
curl \
--user YOUR_ZYTE_API_KEY: \
--header 'Content-Type: application/json' \
--data @input.json \
--compressed \
https://api.zyte.com/v1/extract \
| jq --raw-output .browserHtml \
| xmllint --html --xpath 'count(//*[@class="quote"])' - 2> /dev/null
import com.google.common.collect.ImmutableMap;
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
import java.util.Collections;
import java.util.Map;
import org.apache.hc.client5.http.classic.methods.HttpPost;
import org.apache.hc.client5.http.impl.classic.CloseableHttpClient;
import org.apache.hc.client5.http.impl.classic.HttpClients;
import org.apache.hc.core5.http.ContentType;
import org.apache.hc.core5.http.HttpEntity;
import org.apache.hc.core5.http.HttpHeaders;
import org.apache.hc.core5.http.ParseException;
import org.apache.hc.core5.http.io.entity.EntityUtils;
import org.apache.hc.core5.http.io.entity.StringEntity;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
class Example {
private static final String API_KEY = "YOUR_ZYTE_API_KEY";
public static void main(final String[] args)
throws InterruptedException, IOException, ParseException {
Map<String, Object> action = ImmutableMap.of("action", "scrollBottom");
Map<String, Object> parameters =
ImmutableMap.of(
"url",
"https://quotes.toscrape.com/scroll",
"browserHtml",
true,
"actions",
Collections.singletonList(action));
String requestBody = new Gson().toJson(parameters);
HttpPost request = new HttpPost("https://api.zyte.com/v1/extract");
request.setHeader(HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON);
request.setHeader(HttpHeaders.ACCEPT_ENCODING, "gzip, deflate");
request.setHeader(HttpHeaders.AUTHORIZATION, buildAuthHeader());
request.setEntity(new StringEntity(requestBody));
CloseableHttpClient client = HttpClients.createDefault();
client.execute(
request,
response -> {
HttpEntity entity = response.getEntity();
String apiResponse = EntityUtils.toString(entity, StandardCharsets.UTF_8);
JsonObject jsonObject = JsonParser.parseString(apiResponse).getAsJsonObject();
String browserHtml = jsonObject.get("browserHtml").getAsString();
Document document = Jsoup.parse(browserHtml);
int quoteCount = document.select(".quote").size();
System.out.println(quoteCount);
return null;
});
}
private static String buildAuthHeader() {
String auth = API_KEY + ":";
String encodedAuth = Base64.getEncoder().encodeToString(auth.getBytes());
return "Basic " + encodedAuth;
}
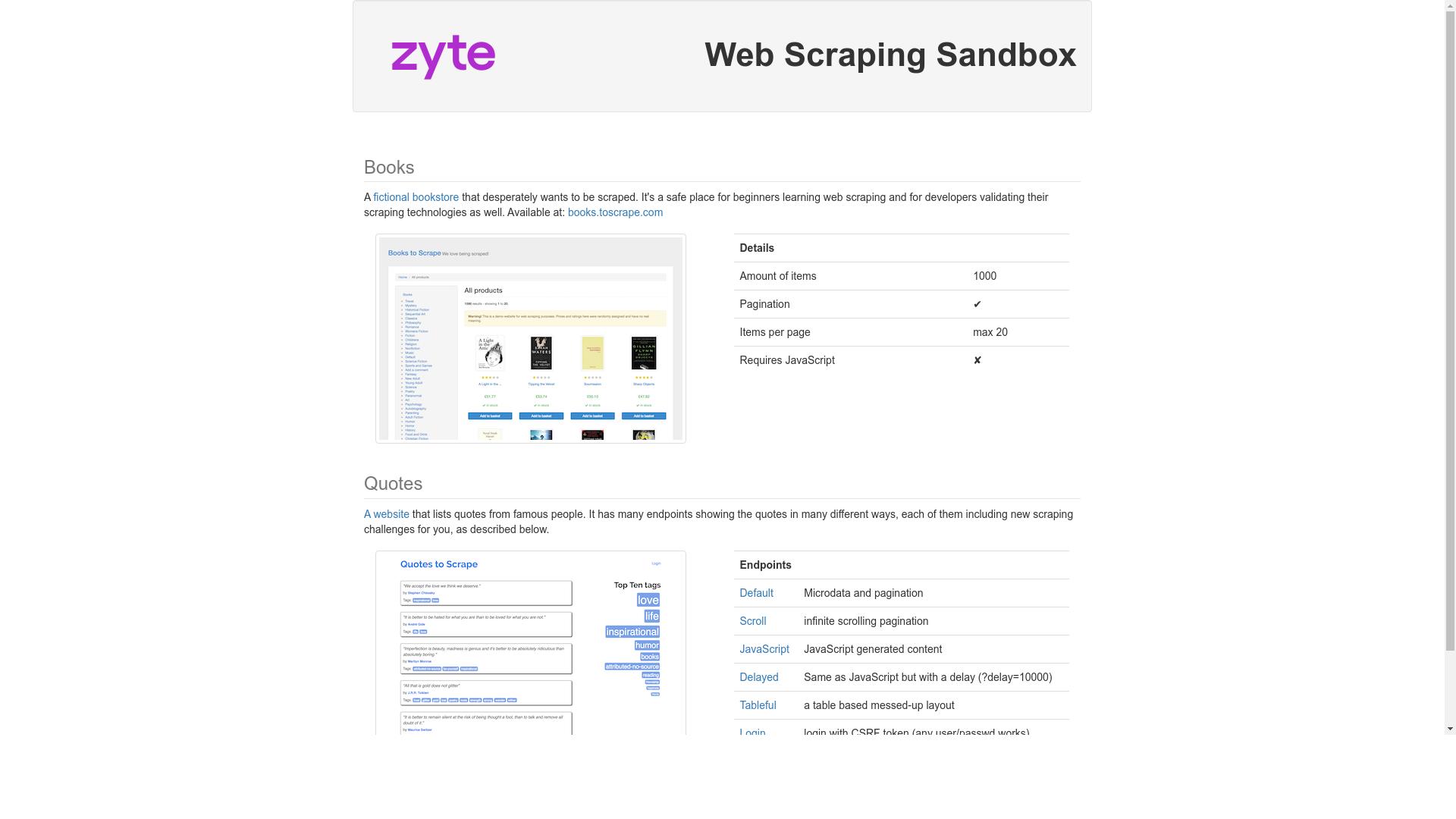
}
const axios = require('axios')
const cheerio = require('cheerio')
axios.post(
'https://api.zyte.com/v1/extract',
{
url: 'https://quotes.toscrape.com/scroll',
browserHtml: true,
actions: [
{
action: 'scrollBottom'
}
]
},
{
auth: { username: 'YOUR_ZYTE_API_KEY' }
}
).then((response) => {
const browserHtml = response.data.browserHtml
const $ = cheerio.load(browserHtml)
const quoteCount = $('.quote').length
})
<?php
$client = new GuzzleHttp\Client();
$response = $client->request('POST', 'https://api.zyte.com/v1/extract', [
'auth' => ['YOUR_ZYTE_API_KEY', ''],
'headers' => ['Accept-Encoding' => 'gzip'],
'json' => [
'url' => 'https://quotes.toscrape.com/scroll',
'browserHtml' => true,
'actions' => [
['action' => 'scrollBottom'],
],
],
]);
$data = json_decode($response->getBody());
$doc = new DOMDocument();
$doc->loadHTML($data->browserHtml);
$xpath = new DOMXPath($doc);
$quote_count = $xpath->query("//*[@class='quote']")->count();
import requests
from parsel import Selector
api_response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={
"url": "https://quotes.toscrape.com/scroll",
"browserHtml": True,
"actions": [
{
"action": "scrollBottom",
},
],
},
)
browser_html = api_response.json()["browserHtml"]
quote_count = len(Selector(browser_html).css(".quote"))
import asyncio
from parsel import Selector
from zyte_api import AsyncZyteAPI
async def main():
client = AsyncZyteAPI()
api_response = await client.get(
{
"url": "https://quotes.toscrape.com/scroll",
"browserHtml": True,
"actions": [
{
"action": "scrollBottom",
},
],
},
)
browser_html = api_response["browserHtml"]
quote_count = len(Selector(browser_html).css(".quote"))
print(quote_count)
asyncio.run(main())
from scrapy import Request, Spider
class QuotesToScrapeComSpider(Spider):
name = "quotes_toscrape_com"
async def start(self):
yield Request(
"https://quotes.toscrape.com/scroll",
meta={
"zyte_api_automap": {
"browserHtml": True,
"actions": [
{
"action": "scrollBottom",
},
],
},
},
)
def parse(self, response):
quote_count = len(response.css(".quote"))
Output:
100
Example: Read from the shadow DOM
Note
Install and configure code example requirements and the Zyte CA certificate to run the example below.
To get content from the shadow DOM, use the evaluate action to create an
invisible DOM element, which you will get in browserHtml, and
fill it with the desired content from the shadow DOM.
Tip
If your evaluate action does not work as expected, check the
actions response field for errors.
The following example code shows how to access the shadow DOM paragraph from
a shadow DOM example in CodePen using the
evaluate action with the following source:
const div = document.createElement('div')
div.setAttribute('id', 'shadow-root-content')
// Hide, in case you also want to take a screenshot.
div.style.display = 'none'
const iframe = document.getElementById('result')
div.innerText = iframe
.contentWindow.document
.getElementById('shadow-root')
.shadowRoot.querySelector('p').textContent
document.body.appendChild(div)
using System;
using System.Collections.Generic;
using System.Net;
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Threading.Tasks;
using System.Xml.XPath;
using HtmlAgilityPack;
HttpClientHandler handler = new HttpClientHandler()
{
AutomaticDecompression = DecompressionMethods.All
};
HttpClient client = new HttpClient(handler);
var apiKey = "YOUR_ZYTE_API_KEY";
var bytes = Encoding.GetEncoding("ISO-8859-1").GetBytes(apiKey + ":");
var auth = System.Convert.ToBase64String(bytes);
client.DefaultRequestHeaders.Add("Authorization", "Basic " + auth);
client.DefaultRequestHeaders.Add("Accept-Encoding", "br, gzip, deflate");
var input = new Dictionary<string, object>(){
{"url", "https://cdpn.io/TLadd/fullpage/PoGoQeV?anon=true&view="},
{"browserHtml", true},
{
"actions",
new List<Dictionary<string, object>>()
{
new Dictionary<string, object>()
{
{"action", "evaluate"},
{"source", @"
const div = document.createElement('div')
div.setAttribute('id', 'shadow-root-content')
div.style.display = 'none'
const iframe = document.getElementById('result')
div.innerText = iframe
.contentWindow.document
.getElementById('shadow-root')
.shadowRoot.querySelector('p').textContent
document.body.appendChild(div)
"}
}
}
}
};
var inputJson = JsonSerializer.Serialize(input);
var content = new StringContent(inputJson, Encoding.UTF8, "application/json");
HttpResponseMessage response = await client.PostAsync("https://api.zyte.com/v1/extract", content);
var body = await response.Content.ReadAsByteArrayAsync();
var data = JsonDocument.Parse(body);
var browserHtml = data.RootElement.GetProperty("browserHtml").ToString();
var htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(browserHtml);
var navigator = htmlDocument.CreateNavigator();
var nodeIterator = (XPathNodeIterator)navigator.Evaluate("//*[@id=\"shadow-root-content\"]/text()");
nodeIterator.MoveNext();
var shadowText = nodeIterator.Current.ToString();
Console.WriteLine(shadowText);
import com.google.common.collect.ImmutableMap;
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
import java.util.Collections;
import java.util.Map;
import org.apache.hc.client5.http.classic.methods.HttpPost;
import org.apache.hc.client5.http.impl.classic.CloseableHttpClient;
import org.apache.hc.client5.http.impl.classic.HttpClients;
import org.apache.hc.core5.http.ContentType;
import org.apache.hc.core5.http.HttpEntity;
import org.apache.hc.core5.http.HttpHeaders;
import org.apache.hc.core5.http.ParseException;
import org.apache.hc.core5.http.io.entity.EntityUtils;
import org.apache.hc.core5.http.io.entity.StringEntity;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
class Example {
private static final String API_KEY = "YOUR_ZYTE_API_KEY";
public static void main(final String[] args)
throws InterruptedException, IOException, ParseException {
Map<String, Object> actions =
ImmutableMap.of(
"action",
"evaluate",
"source",
"const div = document.createElement('div')\n"
+ "div.setAttribute('id', 'shadow-root-content')\n"
+ "div.style.display = 'none'\n"
+ "const iframe = document.getElementById('result')\n"
+ "div.innerText = iframe\n"
+ " .contentWindow.document\n"
+ " .getElementById('shadow-root')\n"
+ " .shadowRoot.querySelector('p').textContent\n"
+ "document.body.appendChild(div)");
Map<String, Object> parameters =
ImmutableMap.of(
"url",
"https://cdpn.io/TLadd/fullpage/PoGoQeV?anon=true&view=",
"browserHtml",
true,
"actions",
Collections.singletonList(actions));
String requestBody = new Gson().toJson(parameters);
HttpPost request = new HttpPost("https://api.zyte.com/v1/extract");
request.setHeader(HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON);
request.setHeader(HttpHeaders.ACCEPT_ENCODING, "gzip, deflate");
request.setHeader(HttpHeaders.AUTHORIZATION, buildAuthHeader());
request.setEntity(new StringEntity(requestBody));
CloseableHttpClient client = HttpClients.createDefault();
client.execute(
request,
response -> {
HttpEntity entity = response.getEntity();
String apiResponse = EntityUtils.toString(entity, StandardCharsets.UTF_8);
JsonObject jsonObject = JsonParser.parseString(apiResponse).getAsJsonObject();
String browserHtml = jsonObject.get("browserHtml").getAsString();
Document document = Jsoup.parse(browserHtml);
String shadowText = document.select("#shadow-root-content").text();
System.out.println(shadowText);
return null;
});
}
private static String buildAuthHeader() {
String auth = API_KEY + ":";
String encodedAuth = Base64.getEncoder().encodeToString(auth.getBytes());
return "Basic " + encodedAuth;
}
}
const axios = require('axios')
const cheerio = require('cheerio')
axios.post(
'https://api.zyte.com/v1/extract',
{
url: 'https://cdpn.io/TLadd/fullpage/PoGoQeV?anon=true&view=',
browserHtml: true,
actions: [
{
action: 'evaluate',
source: `
const div = document.createElement('div')
div.setAttribute('id', 'shadow-root-content')
div.style.display = 'none'
const iframe = document.getElementById('result')
div.innerText = iframe
.contentWindow.document
.getElementById('shadow-root')
.shadowRoot.querySelector('p').textContent
document.body.appendChild(div)
`
}
]
},
{
auth: { username: 'YOUR_ZYTE_API_KEY' }
}
).then((response) => {
const browserHtml = response.data.browserHtml
const $ = cheerio.load(browserHtml)
const shadowText = $('#shadow-root-content').text()
console.log(shadowText)
})
<?php
$client = new GuzzleHttp\Client();
$response = $client->request('POST', 'https://api.zyte.com/v1/extract', [
'auth' => ['YOUR_ZYTE_API_KEY', ''],
'headers' => ['Accept-Encoding' => 'gzip'],
'json' => [
'url' => 'https://cdpn.io/TLadd/fullpage/PoGoQeV?anon=true&view=',
'browserHtml' => true,
'actions' => [
[
'action' => 'evaluate',
'source' => "
const div = document.createElement('div')
div.setAttribute('id', 'shadow-root-content')
div.style.display = 'none'
const iframe = document.getElementById('result')
div.innerText = iframe
.contentWindow.document
.getElementById('shadow-root')
.shadowRoot.querySelector('p').textContent
document.body.appendChild(div)
",
],
],
],
]);
$data = json_decode($response->getBody());
$doc = new DOMDocument();
$doc->loadHTML($data->browserHtml);
$xpath = new DOMXPath($doc);
$shadow_text = $xpath->query("//*[@id='shadow-root-content']")->item(0)->textContent;
echo $shadow_text.PHP_EOL;
import requests
from parsel import Selector
api_response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={
"url": "https://cdpn.io/TLadd/fullpage/PoGoQeV?anon=true&view=",
"browserHtml": True,
"actions": [
{
"action": "evaluate",
"source": """
const div = document.createElement('div')
div.setAttribute('id', 'shadow-root-content')
div.style.display = 'none'
const iframe = document.getElementById('result')
div.innerText = iframe
.contentWindow.document
.getElementById('shadow-root')
.shadowRoot.querySelector('p').textContent
document.body.appendChild(div)
""",
},
],
},
)
browser_html = api_response.json()["browserHtml"]
shadow_text = Selector(browser_html).css("#shadow-root-content::text").get()
print(shadow_text)
import asyncio
from parsel import Selector
from zyte_api import AsyncZyteAPI
async def main():
client = AsyncZyteAPI()
api_response = await client.get(
{
"url": "https://cdpn.io/TLadd/fullpage/PoGoQeV?anon=true&view=",
"browserHtml": True,
"actions": [
{
"action": "evaluate",
"source": """
const div = document.createElement('div')
div.setAttribute('id', 'shadow-root-content')
div.style.display = 'none'
const iframe = document.getElementById('result')
div.innerText = iframe
.contentWindow.document
.getElementById('shadow-root')
.shadowRoot.querySelector('p').textContent
document.body.appendChild(div)
""",
},
],
},
)
browser_html = api_response["browserHtml"]
shadow_text = Selector(browser_html).css("#shadow-root-content::text").get()
print(shadow_text)
asyncio.run(main())
from scrapy import Request, Spider
class CodePenSpider(Spider):
name = "codepen"
async def start(self):
yield Request(
"https://cdpn.io/TLadd/fullpage/PoGoQeV?anon=true&view=",
meta={
"zyte_api_automap": {
"browserHtml": True,
"actions": [
{
"action": "evaluate",
"source": """
const div = document.createElement('div')
div.setAttribute('id', 'shadow-root-content')
div.style.display = 'none'
const iframe = document.getElementById('result')
div.innerText = iframe
.contentWindow.document
.getElementById('shadow-root')
.shadowRoot.querySelector('p').textContent
document.body.appendChild(div)
""",
},
],
},
},
)
def parse(self, response):
shadow_text = response.css("#shadow-root-content::text").get()
print(shadow_text)
Output:
Shadow Paragraph
Action types¶
Zyte API supports 3 types of browser actions:
Generic actions work on every website. They allow you to type text into input fields, emulate mouse input, and wait for events or time.
Special actions expose functionality that requires specific knowledge of the target website, such as using their search box or filling a form.
They are only available for certain websites. To find out if an action is available for a given website, send a test request using that action. If the action is not supported, you will get an error API response indicating so.
Action limits¶
You are free to use as many browser actions as you wish, but total browser execution time is limited to 60 seconds. If your actions are still running by that time, the on-going action is interrupted, follow-up actions are not executed at all, and you get your requested output (browser HTML, screenshot) as it was rendered at that time.
The Zyte API response includes an action key that provides details about
action execution, including elapsedTime, error, and status fields
to help you debug your actions, e.g. to find out which actions were executed
successfully and which actions were not.
Action selectors¶
Browser actions that interact with a webpage element all have a selector
key that allows you to define how to find the target webpage element.
You must define a query to find the target webpage element in the
selector.value field.
You must specify the language of your query in the selector.type field,
which supports the following values: CSS Selector (css), XPath 1.0
(xpath). For information about these query languages, see Learning CSS and
XPath.
Note that selectors cannot interact with iframes or with the shadow DOM, only the evaluate action and browser scripts can.
Wait actions¶
You can use the following browser actions to introduce wait times in your
browser action sequences or in your browser scripts:
waitForSelector, waitForRequest, waitForResponse, and
waitForTimeout.
Whenever you need to wait for something to happen on a webpage, your should
consider using waitForSelector first. It waits for an element matching a
given selector. By default, it waits for a matching
visible element, but you can change selector.state to attached, to
wait for an element to exist regardless of visibility, or to hidden, to
wait for a matching invisible element.
Tip
For a usage example of waitForSelector, see the web scraping
tutorial.
waitForRequest and waitForResponse wait for a request to be sent or for
a response to be received, filtering by URL pattern.
waitForTimeout pauses your sequence of actions or your browser script for
the specified amount of time. Because action run time is limited, you should avoid using this type of action when an
alternative waiting action can replace it. However, this action can be
necessary for certain scenarios, such as following organic website-access
patterns.
Network capture¶
In browser requests, use the networkCapture request field to define filters to capture network responses received during browser rendering (including action execution).
Example
Note
Install and configure code example requirements and the Zyte CA certificate to run the example below.
using System;
using System.Collections.Generic;
using System.Net;
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Threading.Tasks;
HttpClientHandler handler = new HttpClientHandler()
{
AutomaticDecompression = DecompressionMethods.All
};
HttpClient client = new HttpClient(handler);
var apiKey = "YOUR_ZYTE_API_KEY";
var bytes = Encoding.GetEncoding("ISO-8859-1").GetBytes(apiKey + ":");
var auth = System.Convert.ToBase64String(bytes);
client.DefaultRequestHeaders.Add("Authorization", "Basic " + auth);
client.DefaultRequestHeaders.Add("Accept-Encoding", "br, gzip, deflate");
var input = new Dictionary<string, object>(){
{"url", "https://quotes.toscrape.com/scroll"},
{"browserHtml", true},
{
"networkCapture",
new List<Dictionary<string, object>>()
{
new Dictionary<string, object>()
{
{"filterType", "url"},
{"httpResponseBody", true},
{"value", "/api/"},
{"matchType", "contains"}
}
}
}
};
var inputJson = JsonSerializer.Serialize(input);
var content = new StringContent(inputJson, Encoding.UTF8, "application/json");
HttpResponseMessage response = await client.PostAsync("https://api.zyte.com/v1/extract", content);
var apiBody = await response.Content.ReadAsByteArrayAsync();
var data = JsonDocument.Parse(apiBody);
var captureEnumerator = data.RootElement.GetProperty("networkCapture").EnumerateArray();
captureEnumerator.MoveNext();
var capture = captureEnumerator.Current;
var base64Body = capture.GetProperty("httpResponseBody").ToString();
var body = System.Convert.FromBase64String(base64Body);
var captureData = JsonDocument.Parse(body);
var quoteEnumerator = captureData.RootElement.GetProperty("quotes").EnumerateArray();
quoteEnumerator.MoveNext();
var quote = quoteEnumerator.Current;
var authorEnumerator = quote.GetProperty("author").EnumerateObject();
while (authorEnumerator.MoveNext())
{
if (authorEnumerator.Current.Name.ToString() == "name")
{
Console.WriteLine(authorEnumerator.Current.Value.ToString());
break;
}
}
{"url": "https://quotes.toscrape.com/scroll", "browserHtml": true, "networkCapture": [{"filterType": "url", "httpResponseBody": true, "value": "/api/", "matchType": "contains"}]}
zyte-api input.jsonl \
| jq --raw-output ".networkCapture[0].httpResponseBody" \
| base64 --decode \
| jq --raw-output ".quotes[0].author.name"
{
"url": "https://quotes.toscrape.com/scroll",
"browserHtml": true,
"networkCapture": [
{
"filterType": "url",
"httpResponseBody": true,
"value": "/api/",
"matchType": "contains"
}
]
}
curl \
--user YOUR_ZYTE_API_KEY: \
--header 'Content-Type: application/json' \
--data @input.json \
--compressed \
https://api.zyte.com/v1/extract \
| jq --raw-output ".networkCapture[0].httpResponseBody" \
| base64 --decode \
| jq --raw-output ".quotes[0].author.name"
import com.google.common.collect.ImmutableMap;
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
import java.util.Collections;
import java.util.Map;
import org.apache.hc.client5.http.classic.methods.HttpPost;
import org.apache.hc.client5.http.impl.classic.CloseableHttpClient;
import org.apache.hc.client5.http.impl.classic.HttpClients;
import org.apache.hc.core5.http.ContentType;
import org.apache.hc.core5.http.HttpEntity;
import org.apache.hc.core5.http.HttpHeaders;
import org.apache.hc.core5.http.ParseException;
import org.apache.hc.core5.http.io.entity.EntityUtils;
import org.apache.hc.core5.http.io.entity.StringEntity;
class Example {
private static final String API_KEY = "YOUR_ZYTE_API_KEY";
public static void main(final String[] args)
throws InterruptedException, IOException, ParseException {
Map<String, Object> filter =
ImmutableMap.of(
"filterType",
"url",
"httpResponseBody",
true,
"value",
"/api/",
"matchType",
"contains");
Map<String, Object> parameters =
ImmutableMap.of(
"url",
"https://quotes.toscrape.com/scroll",
"browserHtml",
true,
"networkCapture",
Collections.singletonList(filter));
String requestBody = new Gson().toJson(parameters);
HttpPost request = new HttpPost("https://api.zyte.com/v1/extract");
request.setHeader(HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON);
request.setHeader(HttpHeaders.ACCEPT_ENCODING, "gzip, deflate");
request.setHeader(HttpHeaders.AUTHORIZATION, buildAuthHeader());
request.setEntity(new StringEntity(requestBody));
CloseableHttpClient client = HttpClients.createDefault();
client.execute(
request,
response -> {
HttpEntity entity = response.getEntity();
String apiResponse = EntityUtils.toString(entity, StandardCharsets.UTF_8);
JsonObject jsonObject = JsonParser.parseString(apiResponse).getAsJsonObject();
JsonArray captures = jsonObject.get("networkCapture").getAsJsonArray();
JsonObject capture = captures.get(0).getAsJsonObject();
byte[] bodyBytes =
Base64.getDecoder().decode(capture.get("httpResponseBody").getAsString());
String body = new String(bodyBytes, StandardCharsets.UTF_8);
JsonObject data = JsonParser.parseString(body).getAsJsonObject();
JsonObject quote = data.get("quotes").getAsJsonArray().get(0).getAsJsonObject();
String authorName = quote.get("author").getAsJsonObject().get("name").getAsString();
System.out.println(authorName);
return null;
});
}
private static String buildAuthHeader() {
String auth = API_KEY + ":";
String encodedAuth = Base64.getEncoder().encodeToString(auth.getBytes());
return "Basic " + encodedAuth;
}
}
const axios = require('axios')
axios.post(
'https://api.zyte.com/v1/extract',
{
url: 'https://quotes.toscrape.com/scroll',
browserHtml: true,
networkCapture: [
{
filterType: 'url',
httpResponseBody: true,
value: '/api/',
matchType: 'contains'
}
]
},
{
auth: { username: 'YOUR_ZYTE_API_KEY' }
}
).then((response) => {
const capture = response.data.networkCapture[0]
const data = JSON.parse(Buffer.from(capture.httpResponseBody, 'base64'))
console.log(data.quotes[0].author.name)
})
<?php
$client = new GuzzleHttp\Client();
$response = $client->request('POST', 'https://api.zyte.com/v1/extract', [
'auth' => ['YOUR_ZYTE_API_KEY', ''],
'headers' => ['Accept-Encoding' => 'gzip'],
'json' => [
'url' => 'https://quotes.toscrape.com/scroll',
'browserHtml' => true,
'networkCapture' => [
[
'filterType' => 'url',
'httpResponseBody' => true,
'value' => '/api/',
'matchType' => 'contains',
],
],
],
]);
$api_response = json_decode($response->getBody());
$capture = $api_response->networkCapture[0];
$data = json_decode(base64_decode($capture->httpResponseBody));
echo $data->quotes[0]->author->name.PHP_EOL;
import json
from base64 import b64decode
import requests
api_response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={
"url": "https://quotes.toscrape.com/scroll",
"browserHtml": True,
"networkCapture": [
{
"filterType": "url",
"httpResponseBody": True,
"value": "/api/",
"matchType": "contains",
},
],
},
)
capture = api_response.json()["networkCapture"][0]
data = json.loads(b64decode(capture["httpResponseBody"]).decode())
print(data["quotes"][0]["author"]["name"])
import asyncio
import json
from base64 import b64decode
from zyte_api import AsyncZyteAPI
async def main():
client = AsyncZyteAPI()
api_response = await client.get(
{
"url": "https://quotes.toscrape.com/scroll",
"browserHtml": True,
"networkCapture": [
{
"filterType": "url",
"httpResponseBody": True,
"value": "/api/",
"matchType": "contains",
},
],
},
)
capture = api_response["networkCapture"][0]
data = json.loads(b64decode(capture["httpResponseBody"]).decode())
print(data["quotes"][0]["author"]["name"])
asyncio.run(main())
import json
from base64 import b64decode
from scrapy import Request, Spider
class QuotesToScrapeComSpider(Spider):
name = "quotes_toscrape_com"
async def start(self):
yield Request(
"https://quotes.toscrape.com/scroll",
meta={
"zyte_api_automap": {
"browserHtml": True,
"networkCapture": [
{
"filterType": "url",
"httpResponseBody": True,
"value": "/api/",
"matchType": "contains",
},
],
},
},
)
def parse(self, response):
capture = response.raw_api_response["networkCapture"][0]
data = json.loads(b64decode(capture["httpResponseBody"]).decode())
print(data["quotes"][0]["author"]["name"])
Output:
Albert Einstein
See also Use network capture in the web scraping tutorial.
Request headers¶
In browser requests, use the requestHeaders.referer request field to set the Referer header.
Example
Note
Install and configure code example requirements and the Zyte CA certificate to run the example below.
using System.Collections.Generic;
using System.Net;
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Threading.Tasks;
using System.Xml.XPath;
using HtmlAgilityPack;
HttpClientHandler handler = new HttpClientHandler()
{
AutomaticDecompression = DecompressionMethods.All
};
HttpClient client = new HttpClient(handler);
var apiKey = "YOUR_ZYTE_API_KEY";
var bytes = Encoding.GetEncoding("ISO-8859-1").GetBytes(apiKey + ":");
var auth = System.Convert.ToBase64String(bytes);
client.DefaultRequestHeaders.Add("Authorization", "Basic " + auth);
client.DefaultRequestHeaders.Add("Accept-Encoding", "br, gzip, deflate");
var input = new Dictionary<string, object>(){
{"url", "https://httpbin.org/anything"},
{"browserHtml", true},
{
"requestHeaders",
new Dictionary<string, object>()
{
{"referer", "https://example.org/"}
}
}
};
var inputJson = JsonSerializer.Serialize(input);
var content = new StringContent(inputJson, Encoding.UTF8, "application/json");
HttpResponseMessage response = await client.PostAsync("https://api.zyte.com/v1/extract", content);
var body = await response.Content.ReadAsByteArrayAsync();
var data = JsonDocument.Parse(body);
var browserHtml = data.RootElement.GetProperty("browserHtml").ToString();
var htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(browserHtml);
var navigator = htmlDocument.CreateNavigator();
var nodeIterator = (XPathNodeIterator)navigator.Evaluate("//text()");
nodeIterator.MoveNext();
var responseJson = nodeIterator.Current.ToString();
var responseData = JsonDocument.Parse(responseJson);
var headerEnumerator = responseData.RootElement.GetProperty("headers").EnumerateObject();
var headers = new Dictionary<string, string>();
while (headerEnumerator.MoveNext())
{
headers.Add(
headerEnumerator.Current.Name.ToString(),
headerEnumerator.Current.Value.ToString()
);
}
{"url": "https://httpbin.org/anything", "browserHtml": true, "requestHeaders": {"referer": "https://example.org/"}}
zyte-api input.jsonl \
| jq --raw-output .browserHtml \
| xmllint --html --xpath '//text()' - 2> /dev/null \
| jq .headers
{
"url": "https://httpbin.org/anything",
"browserHtml": true,
"requestHeaders": {
"referer": "https://example.org/"
}
}
curl \
--user YOUR_ZYTE_API_KEY: \
--header 'Content-Type: application/json' \
--data @input.json \
--compressed \
https://api.zyte.com/v1/extract \
| jq --raw-output .browserHtml \
| xmllint --html --xpath '//text()' - 2> /dev/null \
| jq .headers
import com.google.common.collect.ImmutableMap;
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
import java.util.Map;
import org.apache.hc.client5.http.classic.methods.HttpPost;
import org.apache.hc.client5.http.impl.classic.CloseableHttpClient;
import org.apache.hc.client5.http.impl.classic.HttpClients;
import org.apache.hc.core5.http.ContentType;
import org.apache.hc.core5.http.HttpEntity;
import org.apache.hc.core5.http.HttpHeaders;
import org.apache.hc.core5.http.ParseException;
import org.apache.hc.core5.http.io.entity.EntityUtils;
import org.apache.hc.core5.http.io.entity.StringEntity;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
class Example {
private static final String API_KEY = "YOUR_ZYTE_API_KEY";
public static void main(final String[] args)
throws InterruptedException, IOException, ParseException {
Map<String, Object> requestHeaders = ImmutableMap.of("referer", "https://example.org/");
Map<String, Object> parameters =
ImmutableMap.of(
"url",
"https://httpbin.org/anything",
"browserHtml",
true,
"requestHeaders",
requestHeaders);
String requestBody = new Gson().toJson(parameters);
HttpPost request = new HttpPost("https://api.zyte.com/v1/extract");
request.setHeader(HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON);
request.setHeader(HttpHeaders.ACCEPT_ENCODING, "gzip, deflate");
request.setHeader(HttpHeaders.AUTHORIZATION, buildAuthHeader());
request.setEntity(new StringEntity(requestBody));
CloseableHttpClient client = HttpClients.createDefault();
client.execute(
request,
response -> {
HttpEntity entity = response.getEntity();
String apiResponse = EntityUtils.toString(entity, StandardCharsets.UTF_8);
JsonObject jsonObject = JsonParser.parseString(apiResponse).getAsJsonObject();
String browserHtml = jsonObject.get("browserHtml").getAsString();
Document document = Jsoup.parse(browserHtml);
JsonObject data = JsonParser.parseString(document.text()).getAsJsonObject();
JsonObject headers = data.get("headers").getAsJsonObject();
Gson gson = new GsonBuilder().setPrettyPrinting().create();
System.out.println(gson.toJson(headers));
return null;
});
}
private static String buildAuthHeader() {
String auth = API_KEY + ":";
String encodedAuth = Base64.getEncoder().encodeToString(auth.getBytes());
return "Basic " + encodedAuth;
}
}
const axios = require('axios')
const cheerio = require('cheerio')
axios.post(
'https://api.zyte.com/v1/extract',
{
url: 'https://httpbin.org/anything',
browserHtml: true,
requestHeaders: {
referer: 'https://example.org/'
}
},
{
auth: { username: 'YOUR_ZYTE_API_KEY' }
}
).then((response) => {
const $ = cheerio.load(response.data.browserHtml)
const data = JSON.parse($.text())
const headers = data.headers
})
<?php
$client = new GuzzleHttp\Client();
$response = $client->request('POST', 'https://api.zyte.com/v1/extract', [
'auth' => ['YOUR_ZYTE_API_KEY', ''],
'headers' => ['Accept-Encoding' => 'gzip'],
'json' => [
'url' => 'https://httpbin.org/anything',
'browserHtml' => true,
'requestHeaders' => [
'referer' => 'https://example.org/',
],
],
]);
$api = json_decode($response->getBody());
$doc = new DOMDocument();
$doc->loadHTML($api->browserHtml);
$data = json_decode($doc->textContent);
$headers = $data->headers;
import json
import requests
from parsel import Selector
api_response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={
"url": "https://httpbin.org/anything",
"browserHtml": True,
"requestHeaders": {
"referer": "https://example.org/",
},
},
)
browser_html = api_response.json()["browserHtml"]
selector = Selector(browser_html)
response_json = selector.xpath("//text()").get()
response_data = json.loads(response_json)
headers = response_data["headers"]
import asyncio
import json
from parsel import Selector
from zyte_api import AsyncZyteAPI
async def main():
client = AsyncZyteAPI()
api_response = await client.get(
{
"url": "https://httpbin.org/anything",
"browserHtml": True,
"requestHeaders": {
"referer": "https://example.org/",
},
}
)
browser_html = api_response["browserHtml"]
selector = Selector(browser_html)
response_json = selector.xpath("//text()").get()
response_data = json.loads(response_json)
print(json.dumps(response_data["headers"], indent=2))
asyncio.run(main())
import json
from scrapy import Request, Spider
class HTTPBinOrgSpider(Spider):
name = "httpbin_org"
async def start(self):
yield Request(
"https://httpbin.org/anything",
headers={"Referer": "https://example.org/"},
meta={
"zyte_api_automap": {
"browserHtml": True,
},
},
)
def parse(self, response):
response_json = response.xpath("//text()").get()
response_data = json.loads(response_json)
headers = response_data["headers"]
Output ("Referer" line):
"Referer": "https://example.org/",
At the moment, only the Referer header can be overridden this way. If you need to override additional headers, use HTTP requests with their customHttpRequestHeaders request field instead.
Redirection¶
Browser requests always follow HTTP redirection and other URL changes triggered during browser rendering, e.g. by HTML or by JavaScript.
JavaScript¶
Browser requests have JavaScript execution enabled by default for most websites. For some websites, however, JavaScript execution is disabled by default because it helps avoiding bans or automating extraction.
Use the javascript request field to force whether or not JavaScript execution should be enabled on a browser request.
Example
Note
Install and configure code example requirements and the Zyte CA certificate to run the example below.
using System.Collections.Generic;
using System.Net;
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Threading.Tasks;
using System.Xml.XPath;
using HtmlAgilityPack;
HttpClientHandler handler = new HttpClientHandler()
{
AutomaticDecompression = DecompressionMethods.All
};
HttpClient client = new HttpClient(handler);
var apiKey = "YOUR_ZYTE_API_KEY";
var bytes = Encoding.GetEncoding("ISO-8859-1").GetBytes(apiKey + ":");
var auth = System.Convert.ToBase64String(bytes);
client.DefaultRequestHeaders.Add("Authorization", "Basic " + auth);
client.DefaultRequestHeaders.Add("Accept-Encoding", "br, gzip, deflate");
var input = new Dictionary<string, object>(){
{"url", "https://www.whatismybrowser.com/detect/is-javascript-enabled"},
{"browserHtml", true},
{"javascript", false}
};
var inputJson = JsonSerializer.Serialize(input);
var content = new StringContent(inputJson, Encoding.UTF8, "application/json");
HttpResponseMessage response = await client.PostAsync("https://api.zyte.com/v1/extract", content);
var body = await response.Content.ReadAsByteArrayAsync();
var data = JsonDocument.Parse(body);
var browserHtml = data.RootElement.GetProperty("browserHtml").ToString();
var htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(browserHtml);
var navigator = htmlDocument.CreateNavigator();
var nodeIterator = (XPathNodeIterator)navigator.Evaluate("//*[@id=\"detected_value\"]/text()");
nodeIterator.MoveNext();
var isJavaScriptEnabled = nodeIterator.Current.ToString();
{"url": "https://www.whatismybrowser.com/detect/is-javascript-enabled", "browserHtml": true, "javascript": false}
zyte-api input.jsonl \
| jq --raw-output .browserHtml \
| xmllint --html --xpath '//*[@id="detected_value"]/text()' - 2> /dev/null
{
"url": "https://www.whatismybrowser.com/detect/is-javascript-enabled",
"browserHtml": true,
"javascript": false
}
curl \
--user YOUR_ZYTE_API_KEY: \
--header 'Content-Type: application/json' \
--data @input.json \
--compressed \
https://api.zyte.com/v1/extract \
| jq --raw-output .browserHtml \
| xmllint --html --xpath '//*[@id="detected_value"]/text()' - 2> /dev/null
import com.google.common.collect.ImmutableMap;
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
import java.util.Map;
import org.apache.hc.client5.http.classic.methods.HttpPost;
import org.apache.hc.client5.http.impl.classic.CloseableHttpClient;
import org.apache.hc.client5.http.impl.classic.HttpClients;
import org.apache.hc.core5.http.ContentType;
import org.apache.hc.core5.http.HttpEntity;
import org.apache.hc.core5.http.HttpHeaders;
import org.apache.hc.core5.http.ParseException;
import org.apache.hc.core5.http.io.entity.EntityUtils;
import org.apache.hc.core5.http.io.entity.StringEntity;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
class Example {
private static final String API_KEY = "YOUR_ZYTE_API_KEY";
public static void main(final String[] args)
throws InterruptedException, IOException, ParseException {
Map<String, Object> parameters =
ImmutableMap.of(
"url",
"https://www.whatismybrowser.com/detect/is-javascript-enabled",
"browserHtml",
true,
"javascript",
false);
String requestBody = new Gson().toJson(parameters);
HttpPost request = new HttpPost("https://api.zyte.com/v1/extract");
request.setHeader(HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON);
request.setHeader(HttpHeaders.ACCEPT_ENCODING, "gzip, deflate");
request.setHeader(HttpHeaders.AUTHORIZATION, buildAuthHeader());
request.setEntity(new StringEntity(requestBody));
CloseableHttpClient client = HttpClients.createDefault();
client.execute(
request,
response -> {
HttpEntity entity = response.getEntity();
String apiResponse = EntityUtils.toString(entity, StandardCharsets.UTF_8);
JsonObject jsonObject = JsonParser.parseString(apiResponse).getAsJsonObject();
String browserHtml = jsonObject.get("browserHtml").getAsString();
Document document = Jsoup.parse(browserHtml);
String isJavaScriptEnabled = document.select("#detected_value").text();
System.out.println(isJavaScriptEnabled);
return null;
});
}
private static String buildAuthHeader() {
String auth = API_KEY + ":";
String encodedAuth = Base64.getEncoder().encodeToString(auth.getBytes());
return "Basic " + encodedAuth;
}
}
const axios = require('axios')
const cheerio = require('cheerio')
axios.post(
'https://api.zyte.com/v1/extract',
{
url: 'https://www.whatismybrowser.com/detect/is-javascript-enabled',
browserHtml: true,
javascript: false
},
{
auth: { username: 'YOUR_ZYTE_API_KEY' }
}
).then((response) => {
const $ = cheerio.load(response.data.browserHtml)
const isJavaScriptEnabled = $('#detected_value').text()
})
<?php
$client = new GuzzleHttp\Client();
$response = $client->request('POST', 'https://api.zyte.com/v1/extract', [
'auth' => ['YOUR_ZYTE_API_KEY', ''],
'headers' => ['Accept-Encoding' => 'gzip'],
'json' => [
'url' => 'https://www.whatismybrowser.com/detect/is-javascript-enabled',
'browserHtml' => true,
'javascript' => false,
],
]);
$api = json_decode($response->getBody());
$doc = new DOMDocument();
$doc->loadHTML($api->browserHtml);
$xpath = new DOMXPath($doc);
$is_javascript_enabled = $xpath->query("//*[@id='detected_value']")->item(0)->textContent;
import requests
from parsel import Selector
api_response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={
"url": "https://www.whatismybrowser.com/detect/is-javascript-enabled",
"browserHtml": True,
"javascript": False,
},
)
browser_html = api_response.json()["browserHtml"]
selector = Selector(browser_html)
is_javascript_enabled: str = selector.css("#detected_value::text").get()
import asyncio
from parsel import Selector
from zyte_api import AsyncZyteAPI
async def main():
client = AsyncZyteAPI()
api_response = await client.get(
{
"url": "https://www.whatismybrowser.com/detect/is-javascript-enabled",
"browserHtml": True,
"javascript": False,
}
)
browser_html = api_response["browserHtml"]
selector = Selector(browser_html)
is_javascript_enabled = selector.css("#detected_value::text").get()
print(is_javascript_enabled)
asyncio.run(main())
from scrapy import Request, Spider
class WhatIsMyBrowserComSpider(Spider):
name = "whatismybrowser_com"
async def start(self):
yield Request(
"https://www.whatismybrowser.com/detect/is-javascript-enabled",
meta={
"zyte_api_automap": {
"browserHtml": True,
"javascript": False,
},
},
)
def parse(self, response):
is_javascript_enabled: str = response.css("#detected_value::text").get()
Output:
No